In the last chapter, we covered creating a strongly typed data model Fact class for the “/Fact” endpoint. Now that we have the basics down, let’s try a more advanced data model: Breed
https://docs.thecatapi.com/api-reference/models/breed
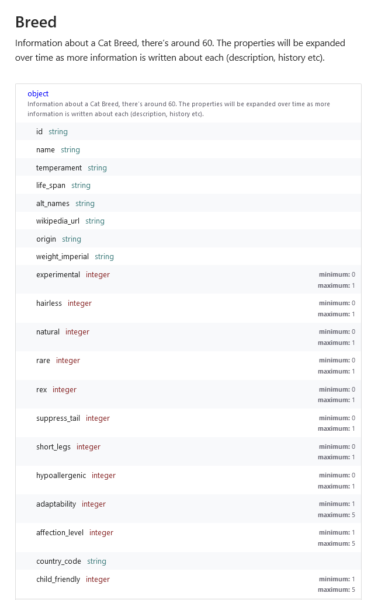
Taking one look at this data model, your eyes just start to glaze over, right? Write a strong data model for that?!? You must be crazy!
No, what we’re going to do is leverage a website to write our Python code for us.
First, we’re going to retrieve a single instance of a breed by using Postman and perform a GET on the following URL: https://api.thecatapi.com/v1/breeds
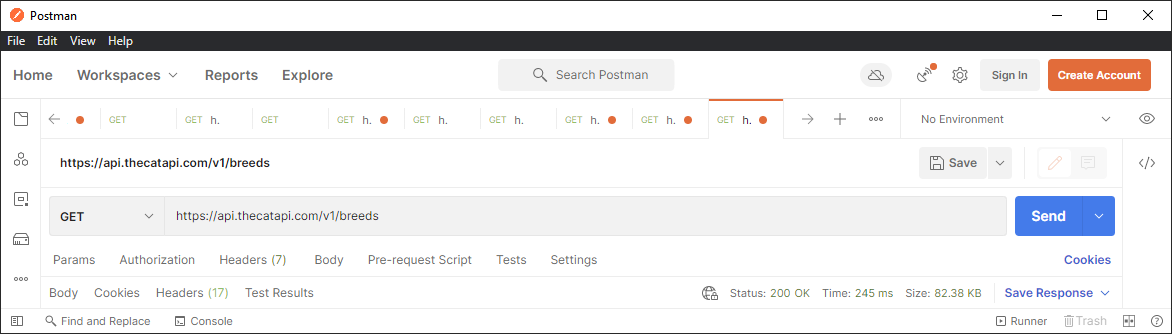
It should return a List of a Dictionaries each containing a unique Breed. We only need 1 instance, so let’s grab the first one.
{
"weight": {
"imperial": "7 - 10",
"metric": "3 - 5"
},
"id": "abys",
"name": "Abyssinian",
"cfa_url": "http://cfa.org/Breeds/BreedsAB/Abyssinian.aspx",
"vetstreet_url": "http://www.vetstreet.com/cats/abyssinian",
"vcahospitals_url": "https://vcahospitals.com/know-your-pet/cat-breeds/abyssinian",
"temperament": "Active, Energetic, Independent, Intelligent, Gentle",
"origin": "Egypt",
"country_codes": "EG",
"country_code": "EG",
"description": "The Abyssinian is easy to care for, and a joy to have in your home. They’re affectionate cats and love both people and other animals.",
"life_span": "14 - 15",
"indoor": 0,
"lap": 1,
"alt_names": "",
"adaptability": 5,
"affection_level": 5,
"child_friendly": 3,
"dog_friendly": 4,
"energy_level": 5,
"grooming": 1,
"health_issues": 2,
"intelligence": 5,
"shedding_level": 2,
"social_needs": 5,
"stranger_friendly": 5,
"vocalisation": 1,
"experimental": 0,
"hairless": 0,
"natural": 1,
"rare": 0,
"rex": 0,
"suppressed_tail": 0,
"short_legs": 0,
"wikipedia_url": "https://en.wikipedia.org/wiki/Abyssinian_(cat)",
"hypoallergenic": 0
}Next, open this website in your web browser: https://app.quicktype.io/
In the box in the upper-right corner:
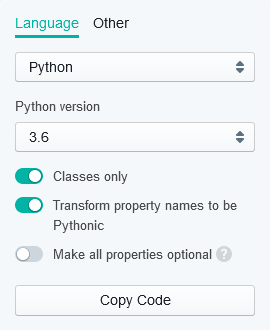
- select
Pythonversion3.6 - turn ON
Classes only - turn ON
Transform property names to be Pythonic - leave OFF
Make all properties optional
In the upper left side, Name the class Breed and make sure Source Type is JSON.
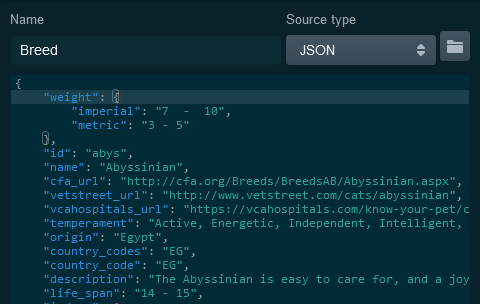
Then just paste your JSON text into the column on the left side. And with that, the site should auto-generate your Python 3.6 code.
Interestingly, this code generator has detected a Class within a Class and has generated two (2) classes, as such. Additionally, this generator also creates unnecessary class variable types. So when we copy this code over to our models.py file, we can delete these class variables and tighten up our data model code a good bit. It should look like this:
class Weight:
def __init__(self, imperial: str, metric: str) -> None:
self.imperial = imperial
self.metric = metric
class Breed:
def __init__(self, weight: Weight, id: str, name: str, cfa_url: str, vetstreet_url: str, vcahospitals_url: str, temperament: str, origin: str, country_codes: str, country_code: str, description: str, life_span: str, indoor: int, lap: int, alt_names: str, adaptability: int, affection_level: int, child_friendly: int, dog_friendly: int, energy_level: int, grooming: int, health_issues: int, intelligence: int, shedding_level: int, social_needs: int, stranger_friendly: int, vocalisation: int, experimental: int, hairless: int, natural: int, rare: int, rex: int, suppressed_tail: int, short_legs: int, wikipedia_url: str, hypoallergenic: int) -> None:
self.weight = weight
self.id = id
self.name = name
self.cfa_url = cfa_url
self.vetstreet_url = vetstreet_url
self.vcahospitals_url = vcahospitals_url
self.temperament = temperament
self.origin = origin
self.country_codes = country_codes
self.country_code = country_code
self.description = description
self.life_span = life_span
self.indoor = indoor
self.lap = lap
self.alt_names = alt_names
self.adaptability = adaptability
self.affection_level = affection_level
self.child_friendly = child_friendly
self.dog_friendly = dog_friendly
self.energy_level = energy_level
self.grooming = grooming
self.health_issues = health_issues
self.intelligence = intelligence
self.shedding_level = shedding_level
self.social_needs = social_needs
self.stranger_friendly = stranger_friendly
self.vocalisation = vocalisation
self.experimental = experimental
self.hairless = hairless
self.natural = natural
self.rare = rare
self.rex = rex
self.suppressed_tail = suppressed_tail
self.short_legs = short_legs
self.wikipedia_url = wikipedia_url
self.hypoallergenic = hypoallergenicLet’s test our new data models out in the Python Console (REPL) by requesting all the Breeds from TheCatApi and pushing them into a list of Breed data objects:
from thecatapi.rest_adapter import RestAdapter
from thecatapi.models import Weight, Breed
catapi = RestAdapter()
result = catapi.get("/breeds")
breed_list = []
for d in result.data:
breed_list.append(Breed(**d))Traceback (most recent call last): File "", line 2, in TypeError: __init__() missing 3 required positional arguments: 'cfa_url', 'vcahospitals_url', and 'lap'
Well, that’s disappointing! What went wrong?
Looking at the exception, we can see that there are 3 mandatory parameters in the constructor __init__ that did not receive any data. So when we tried to take the dictionary d and unpack it (using **) into the Breed class, we didn’t have the right keys to give to it. That’s weird, right?
If we look at the first entry in our result.data dictionary, we can see that entry 0 has all those fields. What about the next one?
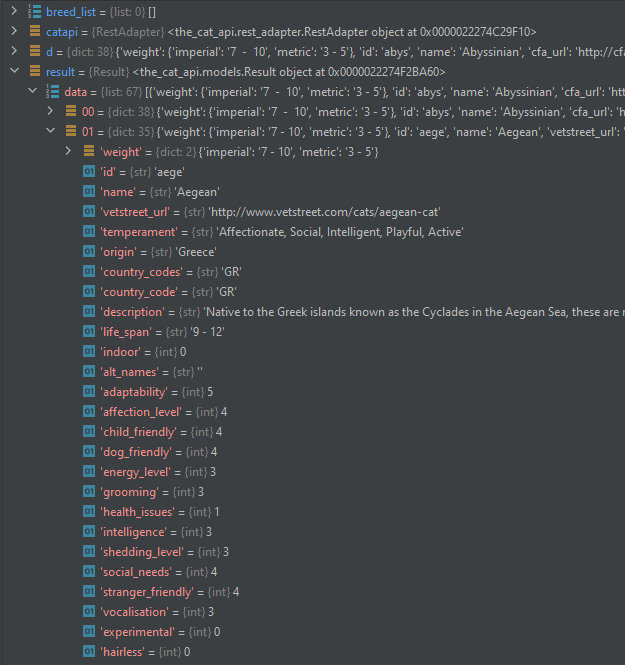
Nope, it’s missing those 3 fields: cfa_url, vcahospitals_url, and lap
How to handle JSON with varying data
- Make some (or all) parameters in the constructor optional
- Only include fields that will always be there and leverage
**kwargsto pick up extraneous fields - Do both!
Let’s start with the first technique!
Technique #1: Make some parameters optional. Here’s our Breed class with its constructor. The missing fields were: cfa_url, vcahospitals_url, and lap
class Breed:
def __init__(self, weight: Weight, id: str, name: str, cfa_url: str, vetstreet_url: str, vcahospitals_url: str, temperament: str, origin: str, country_codes: str, country_code: str, description: str, life_span: str, indoor: int, lap: int, alt_names: str, adaptability: int, affection_level: int, child_friendly: int, dog_friendly: int, energy_level: int, grooming: int, health_issues: int, intelligence: int, shedding_level: int, social_needs: int, stranger_friendly: int, vocalisation: int, experimental: int, hairless: int, natural: int, rare: int, rex: int, suppressed_tail: int, short_legs: int, wikipedia_url: str, hypoallergenic: int) -> None:We can change those values to optional by giving them safe default values:
class Breed:
def __init__(self, weight: Weight, id: str, name: str, cfa_url: str = '', vetstreet_url: str = '', vcahospitals_url: str = '', temperament: str, origin: str, country_codes: str, country_code: str, description: str, life_span: str, indoor: int, lap: int = 0, alt_names: str, adaptability: int, affection_level: int, child_friendly: int, dog_friendly: int, energy_level: int, grooming: int, health_issues: int, intelligence: int, shedding_level: int, social_needs: int, stranger_friendly: int, vocalisation: int, experimental: int, hairless: int, natural: int, rare: int, rex: int, suppressed_tail: int, short_legs: int, wikipedia_url: str, hypoallergenic: int) -> None:We made these parameters optional by giving them a safe default value of empty string (''):
cfa_url: str = '', vetstreet_url: str = '', vcahospitals_url: str = '',We also set lap to a default value of 0. But now we have a different problem. Python requires that all mandatory parameters come first, and then optional parameters with default values come after the mandatory ones, so we have to shuffle our parameters around.
class Breed:
def __init__(self, weight: Weight, id: str, name: str, temperament: str, origin: str, country_codes: str,
country_code: str, description: str, life_span: str, indoor: int, alt_names: str, adaptability: int,
affection_level: int, child_friendly: int, dog_friendly: int, energy_level: int, grooming: int,
health_issues: int, intelligence: int, shedding_level: int, social_needs: int, stranger_friendly: int,
vocalisation: int, experimental: int, hairless: int, natural: int, rare: int, rex: int,
suppressed_tail: int, short_legs: int, wikipedia_url: str, hypoallergenic: int, cfa_url: str = '',
vetstreet_url: str = '', vcahospitals_url: str ='', lap: int = 0, ) -> None:Let’s try running those same 7 lines again…
Traceback (most recent call last):
File "", line 2, in
TypeError: __init__() got an unexpected keyword argument 'cat_friendly'
Ok, we managed to process 10 breeds, but this time we got a keyword that we weren’t anticipating. We could add this parameter to the constructor… Let’s try technique #2 instead.
Technique #2: Leverage **kwargs to our advantage.
Simply put the **kwargs at the end of the constructor parameter list like so:
class Breed:
def __init__(self, weight: Weight, id: str, name: str, temperament: str, origin: str, country_codes: str,
country_code: str, description: str, life_span: str, indoor: int, alt_names: str, adaptability: int,
affection_level: int, child_friendly: int, dog_friendly: int, energy_level: int, grooming: int,
health_issues: int, intelligence: int, shedding_level: int, social_needs: int, stranger_friendly: int,
vocalisation: int, experimental: int, hairless: int, natural: int, rare: int, rex: int,
suppressed_tail: int, short_legs: int, wikipedia_url: str, hypoallergenic: int, cfa_url: str = '',
vetstreet_url: str = '', vcahospitals_url: str ='', lap: int = 0, **kwargs) -> None:And then at the last line in the constructor add the following line:
self.__dict__.update(kwargs)What this line does is take all the “left-over” key/value pairs that didn’t match up with an existing parameter and just stuffs them into the internal class instance variable Dictionary on-the-fly.
The upside to this is that extraneous (read: unexpected) key/value pairs won’t crash your program when trying to push them into a strong data model like this. The downside is that we lose design-time type-hinting for these unknown keys. You will have to test for their existence if you want to use them given that they may or may not be there.
In summary…
- Technique #1 helps when data dictionary passed in has “not enough” key/value pairs.
- Technique #2 helps when data dictionary passed in has “too many” key/value pairs.
A revised and flexible Breed class using these techniques might look like this:
class Breed:
def __init__(self, weight: Weight, id: str, name: str, country_codes: str, country_code: str, description: str,
temperament: str = '', origin: str = '', life_span: str = '', alt_names: str = '',
wikipedia_url: str = '', **kwargs) -> None:
self.weight = weight
self.id = id
self.name = name
self.origin = origin
self.country_codes = country_codes
self.country_code = country_code
self.description = description
self.temperament = temperament
self.life_span = life_span
self.alt_names = alt_names
self.wikipedia_url = wikipedia_url
self.__dict__.update(kwargs)This class will take any key/value pair you throw at it and has type-hinting support for the most important of the fields/properties. Let’s try this out:
from thecatapi.rest_adapter import RestAdapter
from thecatapi.models import Weight, Breed
catapi = RestAdapter()
result = catapi.get("/breeds")
breed_list = []
for d in result.data:
breed_list.append(Breed(**d))
And sure enough, all 67 breeds in the dictionary list are now in a List[Breed]. If we check the name of the first entry in the breed_list like so:
breed_list[0].nameWe see:
'Abyssinian'
Great! At this point, we have one data type that we forgot about. Look at the weight variable in Breeds.
breed_list[0].weight
And we get:{'imperial': '7 - 10', 'metric': '3 - 5'}
Oops. We got back a dictionary. Let’s fix this.
from typing import List, Dict, Union
class Breed:
def __init__(self, weight: Union[Weight,dict], id: str, name: str, country_codes: str, country_code: str,
description: str, temperament: str = '', origin: str = '', life_span: str = '', alt_names: str = '',
wikipedia_url: str = '', **kwargs) -> None:
self.weight = Weight(**weight) if isinstance(weight, dict) else weightWe’ve done 3 small things:
- We imported the
Uniontype from thetypingmodule - We changed the
weightparameter to indicate that it could either be aWeightor adict(that’s what Union means) - Then we test the
weightparameter to see if it is adict, if it is, we unpack the mapping into a Weight object.
If not, then we just copy whatever it is (hopefully a Weight object) into theself.weightinstance.
You may be thinking, “All of this is so complex!” Maybe you’re thinking to yourself, “Hey, I can make a really simple data model!”
class Breed:
def __init__(**kwargs):
self.__dict__.update(kwargs)haha! yeah, I guess that works, but now we’ve completely lost all design-time type hinting. All we’ve managed to do is stuff an external dictionary into the internal Python object __dict__. We’re basically back at square one.
Anyway, figuring out what works and what doesn’t will take some experimentation on your part. As we discovered, the “/breeds” endpoint is fairly consistent about what fields it returns, but occasionally it leaves out some fields while also including unexpected fields.
*** Note: The inconsistency in returned JSON data is fairly common in the world of REST APIs ***
Personally, I always try to figure out what fields I’m definitely using in my program and include those. If I’m being a completion-ist, I will then include all possible fields and set almost all of them (except for perhaps the id) to have default values so that they are optional while still using **kwargs so that any unexpected fields don’t raise exceptions.
Step 10: Inheritance with data models
Source code: https://github.com/PretzelLogix/py-cat-api/tree/09_more_data_models
4 replies on “Step 9: Create more complex Data Models”
[…] Step 9: More complex data models […]
[…] Step 9: More complex data models […]
Hello and thank you for your tutorial, which I’m following to create a wrapper for e-attestation’s Edge API (https://edge.e-attestations.io).
I have a problem with the data model because all the Json request results systematically start with {“content”: …}.
For example, for the “account” endpoint, my model looks like this:
class Account:
content: List[Content]
class Content:
id: int
…
subscriptions: List[Subscription]
class Subscription:
account_id: int
…
My first problem is that all endpoints will have a Content class.
What’s more, when I do :
for d in result.data:
account_list.append(Account(**d))
I get a “TypeError: the_ea_edge_api.models.Account() argument after ** must be a mapping, not str” error that I can’t figure out. can you?
on the other hand, if I do
for d in result.data.get(“content”):
account_list.append(Content(**d))
I have no problem unpacking the data in this data model.
How can I simplify my model by merging class Account and class Content?
Thanks for your help
I don’t think you need a `Content` class. The correct strategy here is what you came up with: `result.data.get(“content”, [])`
(Note the empty list `[]` which is returned in case of `.get()` not finding “content”.)
You may want to hit chapter/step 13 where the topic is “paging the endpoints” where you `yield` the results generator-style, rather than building a list before returning it. (Lazy evaluation vs Eager evaluation)